2023-01-29 by Evrim Öztamur
Beware This article concerns the implementation details of immutable ledgers and working with Xero. Although most parts of it are generic to all immutable ledger structures, some of the heuristics chosen are related to the workings of Xero.
Diff-ing the journals
Following the re-stitching journey, I eventually met the next challenge in line: Finding and visualising the differences between subsequent elements in the chain.
Since the sales tax comparison report post, I went ahead and implemented a system which allows accotron to determine the ’type’ of a journal. The three (plus one mystery) types a journal can have are:
- Creation First journal in the chain.
- Reversal Inverse (all debits are credits and vice versa) of the previous journal in the chain, negating its book impact.1
- Modification Replacing a journal with an adjusted one, after a reversal.
- ??? Not quite a ’type,’ but these are journals which belong to a resource, but have no impact by themselves. More on these soon.
The following screenshot illustrates all three types (newest journal first):
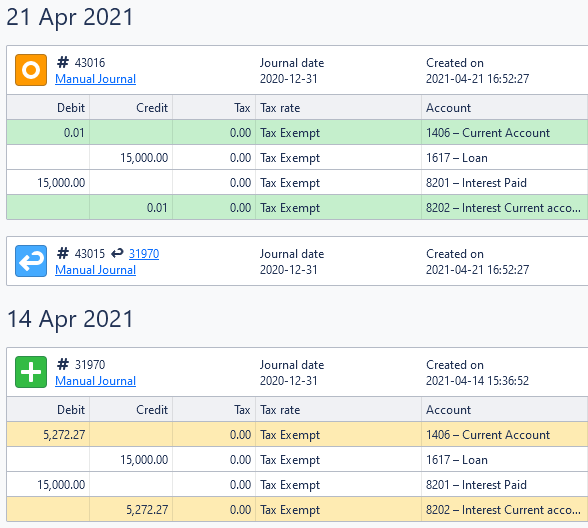
- #31970 Bottom journal (green with plus) is the initial journal in the chain, this is the first instance of a journal appearing for the underlying Xero resource (a manual journal entry).
- #43015 Middle journal (blue with back-arrow) is the reversal of journal #31970 (with a hyperlink to it). Its contents are not shown as it’s the exact inverse of the journal it reverses.
After the booking of #43015, #31970 is no longer present in your reports (as both journals are recorded on the same day, 31 Dec 2020). - #43016 Top journal (orange with circle) is a modification of #31970, whereby its two lines are replaced, with the amount 5,272.27 being changed to 0.01.2
In this post, I will discuss the initial approach I took toward annotating these journals (seems simple, but has some challenges to it) according to this taxonomy. Moreover, I will go through the process of implementing a solution for the accounting equivalent of the longest common subsequence problem that is the basis of data comparison and version control systems.
By the end, the problems associated with this sort of semantic linking should be clear, and their solutions also.
Journal-level annotations
In order to annotate the journals, the most important step is determining which journals are reversals. As the creation journal is always the first journal, this means that all remaining journals—which are not the creation journal or a reversal—are modifications.
The approach to annotating these journals looks like this (in abridged Python):
def annotate_chain(tenant_id, source_id):
The function to annotate the journal chain for a specific (re)source ID (for a given tenant/bookkeeping administration) is as follows:
journal_dict = query_trail_report(
tenant_id=tenant_id,
source_id=source_id,
)
journals = list(journal_dict.values())
journals.sort(key=lambda j: int(j.journal_number), reverse=True)
annotations = {}
query_trail_report returns a dictionary of (ID, journal) for all journals associated with the given resource. Journals are then sorted on their journal numbers, latest first.
The annotations is where we will be storing annotations (prior to attaching them to the journal objects).
for journal in journals:
if journal.is_empty:
annotations[journal.id] = XeroJournalAnnotation.symbolic(journal.id)
journals = [journal for journal in journals if not journal.is_empty]
This is a bit of a teaser for the ???. Here, we annotate these is_empty journals as ‘symbolic.’ Next, we refresh our journals list with the ‘full’ journals.
Next, we begin a new loop whereby we go from the first journal down to the last.3
last_recorded = journals[0]
for i, journal in enumerate(journals):
if i == 0:
create_journal = journals[0]
annotations[create_journal.id] = Annotation.create(create_journal.id)
continue
...
Cutting the loop in the middle here, let’s take a look at what we have. First, we need to declare the last_recorded journal. This is the journal that we know is either a creation or modification. As the first journal of the chain will always be a creation journal, we can already annotate it.
We continue:
...
for j in reversed(range(max(0, i - 2), i)):
is_eq = JournalLine.compare_lines(journal.reversed_lines, journals[j].journal_lines)
if is_eq:
annotations[journal.id] = Annotation.reverse(journals[j].id)
break
...
This inner loop checks the two previous journals (last-first, hence reversed(...)) and checks if the reverse of the current journal (i) equals them. If it does, it annotates the current journal as a reversal of that (j), and break the loop.
...
else:
annotations[journal.id] = Annotation.modify(last_recorded.id)
last_recorded = journal
Python’s for ... else comes in handy for the first time, and in case we did not find any reversals, we can claim that this is a new, unique journal and as such a modification. last_recorded is updated to reflect the new head of the record linked list.
Now, about that filtering stage…
??? — Symbolic journals
While testing the algorithm as described above, I found a fourth type:
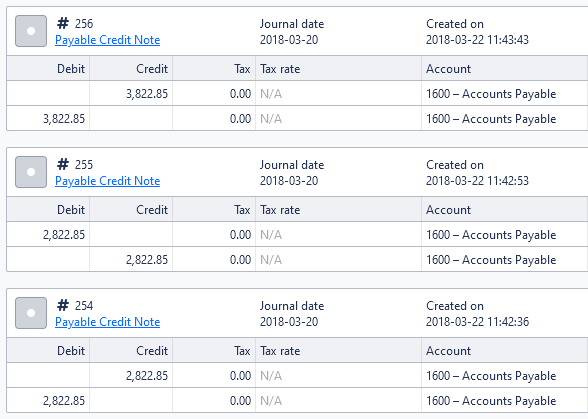
This is truly a trick one, and it took me a while to understand what was going on. These journals appeared in the midst of the chain for an accounts payable credit note. Despite having the same resource ID as the underlying credit note, they are a separate chain of entries:
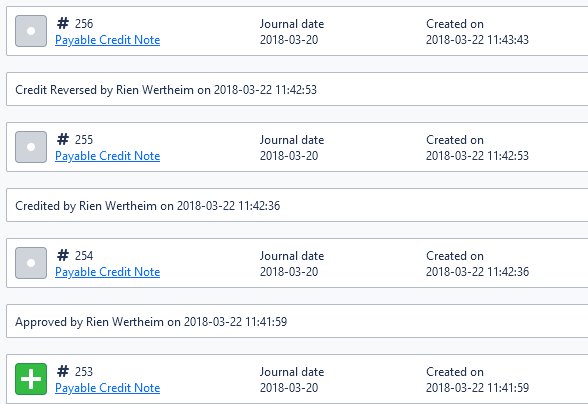
With the comments, it becomes clear that these are (what I settled on calling) symbolic journals. There is no nominal bookkeeping impact by them, but what they do is take out a certain allocation off the initial debit allocation of the credit note and move it (in the same account) against a payable invoice:

I am amazed that Xero decided to record the journals for these adjustments, it’s truly diligent, but an absolute head scratcher when you find out that there is not really a ’tag’ of any sort associated with these journals.
This is why, in order to preserve the integrity of the original chain, these symbolic journals are excluded from the annotation section.
Line-level annotations
You may have noticed a difference comparing the last few screenshots to the first: The lines are not highlighted! Indeed, the journal-level algorithm above only annotates the journals, not their individual lines.
Now that we have a semantic link of create → modify → modify, and so on, we can compare the lines of each of the linked pairs.
A naïve way to go on about it (which is what I went for at first) is comparing the lines of the individual journals, and highlighting lines based on whether they were encountered in a previous journal or not (also abridged Python):
for journal, annotation in annotations.items():
if annotation.is_modification:
related_journal = annotation.related_journal
(added_line_ids, modified_line_ids) = JournalLine.find_delta(
related_journal.journal_lines,
journal.journal_lines,
)
annotation.added_line_ids = added_line_ids
related_journal.annotation.modified_line_ids = modified_line_ids
As the annotations are a linked chain referring to the journal they impact, processing modification journals in any order and comparing their lines to the journal they modify leads to us discovering which lines were added by the modifying journal (green lines), and which lines were missing from the adjusted journal (yellow lines).
The trickery in finding these lies in JournalLine.find_delta:
def find_delta(journal_lines_a, journal_lines_b):
comparison_tuples_a = journal_lines_a.as_comparison_tuple_dict()
comparison_tuples_b = journal_lines_b.as_comparison_tuple_dict()
return (
[
id
for id, t in comparison_tuples_b.items()
if t not in comparison_tuples_a.values()
],
[
id
for id, t in comparison_tuples_a.items()
if t not in comparison_tuples_b.values()
],
)
journal.as_comparison_tuple_dict() yields a dictionary of (ID, comparison tuple), where a ‘comparison tuple’ is a comparable/hash-able tuple consisting of (account ID, net amount, gross amount, tax amount, tax type). These are the tokens that allow you to uniquely identify a journal line.4
It’s important to note here that each journal line has a UUID, i.e. it’s globally unique across the database, not just within the journal. This means that we do not necessarily have a concept of a link between the journal lines. If you edit a line in an invoice, you must use an algorithmic method to best-guess what the actual change made was. Had Xero linked these lines, it would be easy to say ‘journal B’s line #3 is an edit of journal A’s line #2’. Alas, not.
You can see here that the trickery is in the return statements: The list comprehension returns the line IDs which are in A and not in B, and vice versa.
If a line is in the modi-fied (journal A) journal and not in the modi-fying (journal B), that means that this line has been removed, and is marked as ‘modified.’ This will highlight it yellow in the interface.
You can already see here that this is not quite useful:
- A line can be missing from a subsequent journal and be marked ‘modified,’ but it can also be marked as ‘added’ because it wasn’t in the previous journal. How do we visualise this?
- A ‘modified’ line may simply be removed altogether. This differentiation only makes sense when the number of lines between journals is equal.
- Most importantly, we can’t tell what changed!
This sort of simple categorisation is useful only to some extent, but fails to be insightful in cases like the following:
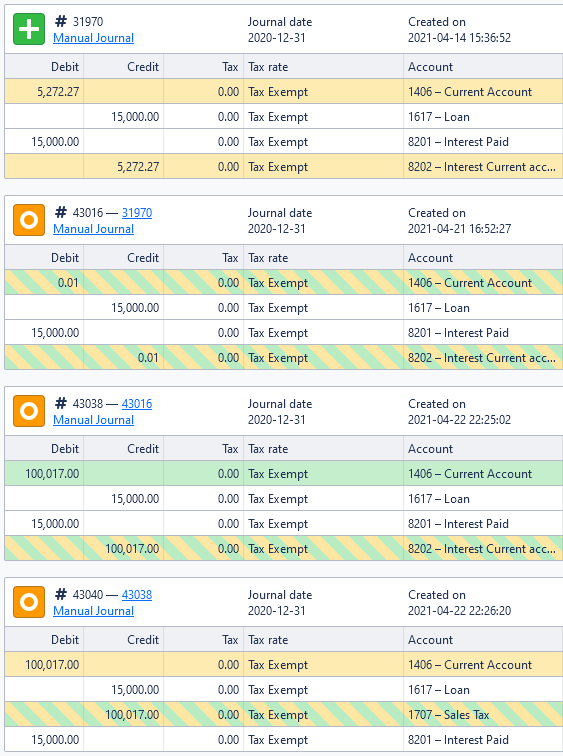
That’s a lot of information, but let’s take it step by step, starting from the top (journals are ordered top-first in this screenshot).
The first journal #31970 has two lines marked as ‘modified,’ these two have amounts 5,272.27 and are replaced in #43016 by 0.01. The third problem becomes very clear in this case—we indeed have no indication in the interface on which numbers are changed.
Keep in mind that by means of the previous set exclusion algorithm, we don’t actually know which lines are connected to which. Only if an entire line is present or missing.
Journal #43038 replaces #43016’s 0.01 amounts with 100,017.00, and as such these lines are marked as ‘added’, and the 0.01 amount of #43016 are marked as ‘modified’ as well as ‘added’. In turn, they are marked with a striped pattern of both. This is already getting complicated, and we’re losing sight of the useful information.
Finally, journal #43040 has its first line of 100,017.00 debited on 1406 marked as modified (with the subsequent journal replacing it), and third line of 100,017.00 credited on… 1707! This line is shown as ‘added’ as the account has changed from 8202 to 1707. It takes a keen eye to see that.
A better option?
We can see that despite this ‘added/modified’ annotation providing some helpful hints so as to which lines are present or missing from one step to the next in our chain, it’s not particularly useful as a version control tool. You still need to do some manual work to determine the actual changes.
What I look for in a version control tool is assistance in seeing how the data moves over time, and to understand why. Here, we have a weak way in doing both. Solving 3. by itself would also help 1. and 2., and it seems that there’s a way to rephrase the problem in a way that resembles the longest common subsequence (LCS) problem.5 It is perhaps better phrased as the ‘closest akin sequence’ problem.
Actually comparing the journals
What would be a lot more useful to have is a view like the following:
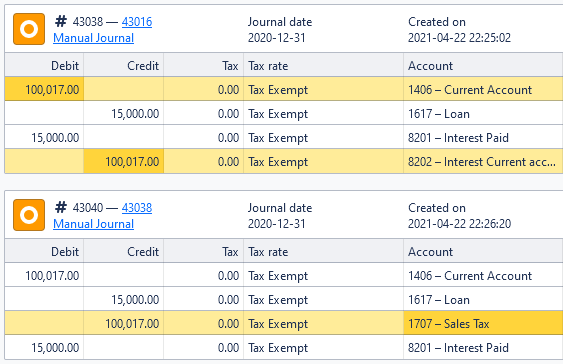
Here, the major difference is that we’re now marking with a different process: Each modified row (and its adjusted cell) gets highlighted, and the changed cells are clearly visible.
This is the same example as the one above (the last two journals), but here we can clearly see which cells have been adjusted. Previously, finding that the account number has changed from 8202 to 1707 was challenging as there was no hint, but here, the cell is highlighted. It’s also obvious that no other adjustments are made to that line.
So, you may think to yourself, how is this difficult? You just compare the lines and find what’s different. That is indeed true, but any of these cells could be changed, and there is no ordering to the rows.
Had these rows been ordered in the same manner in each journal, we could even use the diff utility itself to get the results: This would have made it such that insertions and removals on a line-basis would be shown, and with a special terminator character between the cells, we would get subsequence (cell) matches too. Unfortunately, we also cannot pick a heuristic based on sorting, as any of the cells’ value changing will re-order the two journals.
In turn, we need to go ahead and build a distance matrix of some sort between two journals’ lines.
Distance between lines
I prepared a sample case that better illustrates the complexity (as I couldn’t dig through to find a real-life case, but rest assured this is not a rare one):
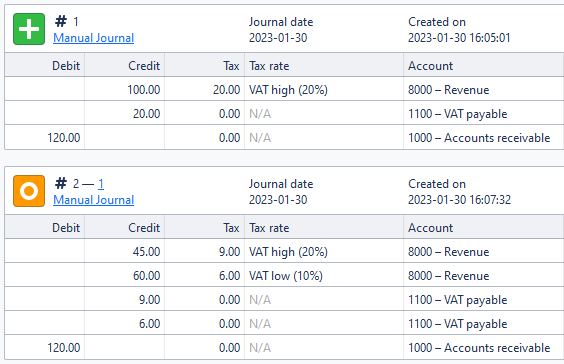
What happened here is that the first line of 100.00 in sales with a 20% tax was split between 45.00 with a 20% tax and 60.00 with a 10% tax. Honest mistake, honest adjustment.
So, we have a minor problem here, where we need to figure out which lines are adjusted into what. I described above that it was the 100.00 line that was split into 45.00 and 60.00, but the VAT payable amount was also split into two, one per item (which is not how Xero handles it, it sums them up, but this makes for a better example!)
The approach that I settled with is in three steps:
- Get rid of the lines that remained the same.
- With the remaining lines, compare each pair and compute the edit distance.
- ‘Pop’ the edits with the smallest distances until no pairing is possible.
My Python implementation of this algorithm starts off like so:
def find_deltas(journal_lines_from, journal_lines_to):
The find_deltas function will return a dictionary of journal IDs with a bool list corresponding to the structure of a comparison tuple, with each element being the equality between the two corresponding cells in the tuples.
comparison_tuples_from_dict = journal_lines_from.as_comparison_tuple_dict()
comparison_tuples_to_dict = journal_lines_to.as_comparison_tuple_dict()
The same conversion occurs for the ‘from’ (original) and ’to’ (modification) journals.
found_from = set()
found_to = set()
for jl_id_from, ct_from in comparison_tuples_from_dict.items():
for jl_id_to, ct_to in comparison_tuples_to_dict.items():
if (
jl_id_to not in found_to
and jl_id_from not in found_from
and ct_from == ct_to
):
found_from.add(jl_id_from)
found_to.add(jl_id_to)
break
The previous solution worked out the equality between lines with a set intersection. The issue is that there may be multiple lines with the exact same comparison tuples. Unlikely, but possible. In turn, we don’t want to remove 2 lines for 1, for example.
Performing the inverse is the correct way to loop in this case (avoiding removals in the loop), where we collect the pairs we successfully match…
for jl_id_to, jl_id_from in zip(found_to, found_from):
del comparison_tuples_from_dict[jl_id_from]
del comparison_tuples_to_dict[jl_id_to]
…and then remove them from the initial dictionaries.
pair_distances = {}
for jl_id_from, ct_from in comparison_tuples_from_dict.items():
for jl_id_to, ct_to in comparison_tuples_to_dict.items():
pair_distances[
(jl_id_from, jl_id_to)
] = XeroJournalLine.comparison_tuple_distance(ct_from, ct_to)
Here we have the base n × m quadratic comparison, where we check all the unmatched lines from the ‘from’ and ’to’ journals. The comparison_tuple_distance is a function which gives the number of edits necessary from one tuple to the next (a move from credit to debit and vice versa, i.e. a sign change, is an edit as well). For the two following lines, the edit distance would be 2, as the net amount and tax rate are both changed:
| Debit | Credit | Tax | Tax Rate | Account | |
|---|---|---|---|---|---|
| From L1 | 100.00 | 20.00 | VAT high (20%) | 8000 – Revenue | |
| To L2 | 60.00 | 6.00 | VAT low (10%) | 8000 – Revenue |
The major complexity factor comes from this evaluation, where we need to compute a matrix like the following:
| To L1 | To L2 | To L3 | To L4 | |
|---|---|---|---|---|
| From L1 | 1 | 2 | 3 | 3 |
| From L2 | 3 | 3 | 1 | 2 |
As we are seeking the lowest edit distances, you can already tell ‘from line 1’ and ’to line 1’, and ‘from line 2’ and ’to line 3’ will be matched!
pair_distances = sorted(
pair_distances.items(), key=lambda item: item[1], reverse=True
)
Once the matrix (a dictionary keyed by (from ID, to ID), with values as the edit distance) is computed, it is sorted from smallest to largest. We need then pair each of the to IDs to an evaluated pair. Because we sorted by distance, we know this to be the shortest distance.
found_deltas = {}
for pair_ids, pair_dist in pair_distances:
if pair_ids[1] not in found_deltas and pair_dist < 3:
found_deltas[pair_ids[1]] = XeroJournalLine.comparison_tuple_match(
comparison_tuples_to_dict[pair_ids[1]],
comparison_tuples_from_dict[pair_ids[0]],
)
return found_deltas
Ultimately, this process leads us to our ‘diff,’ which we can visualise like so for a delta tuple of debit, credit, tax, and account (also abridged output):
<JournalLine #1: ef0cdae1-cf86-400e-be07-9b7d99ab34b2>:
(false, true, false, false)
<JournalLine #3: 213df2b9-551c-4334-93e8-f78e2e323ba0>:
(false, true, false, false)
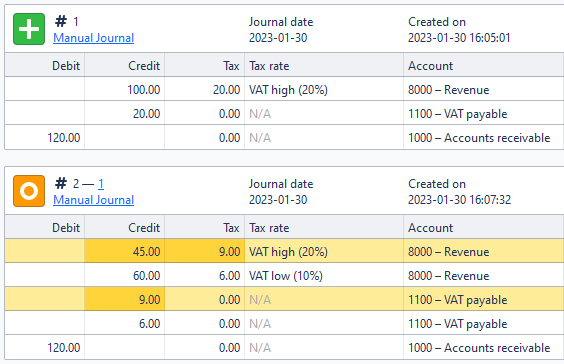
The fourth step
After all edited and editing lines have been paired up, the remaining lines in the previous journal are removed, and ones remaining in the modifying journals are additions. With a filtering heuristic claiming that a pair with more than two adjustments is not the same line, we can get very decent results:
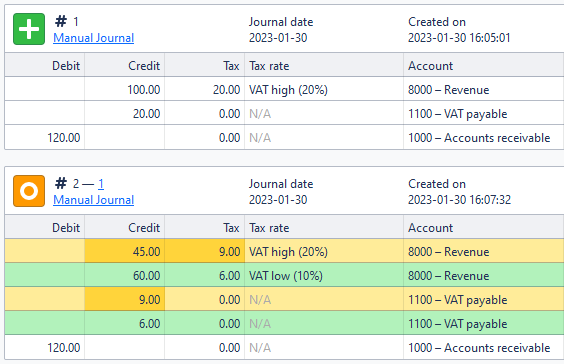
As the lines relating to the 10% line are not matched to any of the previous lines as a modification, we can mark those as new, or ‘added.’
The modified function ends with the following:
found_additions = [
jl_to_id
for jl_to_id in comparison_tuples_to_dict
if jl_to_id not in found_deltas
]
return found_deltas, found_additions
Wrapping it all up
I thought that having a chain of linked journals would be straightforward to manage and easy to deal with. Boy, was I wrong. A lot goes into designing a system that is useful. Turning the data in the system into a format that creates value requires a very strong understanding of the data, the quirks of the system that produces the data, and the context in which the resulting visualisations will be evaluated.
So as to not overcrowd this post (and because I have not yet decided on a visualisation), I excluded the discussion on visualising removed lines. Logically, a line removed is one that neither has an exact counterpart nor is modified in the next journal. Should not be hard to implement.
This is a major milestone nonetheless! The in-depth journal chain analyses will hopefully come in handy to the few who will need it.
Once again, I discuss these and some other implementation concerns over at another article.
-
The sales tax comparison report post has an example of how this works. In short, if you have two journals on the same date, where all lines of the journal are inverted, they will not have any impact on your figures. If they are not on the same date, this is likely to record a deferral. ↩︎
-
Conventionally used as a placeholder without removing the line, in this case there was likely a reassessment of the interest rate. ↩︎
-
The algorithm used to in reverse, that is last-first. Reviewing the behaviour, I did not discover any problems with the results. However, this may not be correct: There may be fail cases where it incorrectly identifies the latest modification as being the reversal of the penultimate journal, which is the reversal of the third-from-last. I initially had some difficulty implementing a forward-looking search, but replaced the reverse implementation while writing this article at the last minute… The current implementation is easier to explain and more concise. ↩︎
-
Line descriptions are missing here, as they usually suffer from minute changes that are not significant (it’s preferable to have to be recorded as a chain of reversals). ↩︎
-
I haven’t found a framing for this exact problem. The main way it differs from the LCS is that the ordering is not known, and does not matter. However, the way in which the solution works by means of generating a distance matrix is very similar. ↩︎