2023-01-08 by Evrim Öztamur
accotron devlog for 2023W02
Since the last devlog, I got distracted by various life-stuff like contract work, Christmas, and Advent of Code:

I finished this year in Rust once again, not having used it over the last year. It took a couple days to get back into the ergonomics, but I noticed that I was seldom fighting the borrow checker, and was able to write code much more easily. I have worked on a couple of Rust projects throughout the year—including a video game prototype using wgpu-rs, implementing a 3D renderer, a voxel model builder, and an object picking buffer—but hadn’t touched it in a quite a while regardless.
accotron did not see much love in the meantime, unfortunately, but I managed to get quite a bit of work done on a small video game I’m working on (also in Rust, but using wasm-bindgen to target browsers). I will likely begin a devlog for that one separately.
Now, it’s business time once again!
Journal annotations
I realised that one of the issues with the design of the existing design of the journals is the way the annotation polymorphism is designed. The current format of having three variants JournalCreate, JournalModify, and JournalReverse make templating rather difficult. In actuality, the journal purpose is simply a tag without additional metadata. Currently, the JournalModify annotation contains the added_line_ids attribute, which is a list of journal line UUIDs that the parent journal did not contain an equivalent of (which means that they are additions).
However, I noticed that when I visualised only the added lines, it made it difficult to understand how the new journal impacted a previous one in the chain. In turn, I have to include a reversed_line_ids list too. The problem is that a modification journal can also have lines removed, and so can a create journal.
The alternate design I’m trying out right now will have both added_line_ids and reversed_line_ids lists, and the respective ‘CR(U)D’ tag on a single JournalAnnotation object.
Added benefits are that visualising reversed lines will now be more straightforward and share the logic across all journals, and serialising the annotations to store on the database will be more straightforward too.
Annotation storage
Generating the annotations is fast enough that I think it will be included as a post-processing step after loading all journals (during organisation initialisation) and whenever more journals are added. On the other hand, generating them on the fly makes them difficult to refer to these annotations and their contents (like added/reversed lines) when accessing them from other reports. These reports will list tens or hundreds of journals at once, and caching the annotations is vital.
I will be using the json_serializer/deserializer properties available through SQLAlchemy’s create_engine, and use a helper JSON serializer library to address this. The post-processing step will resolve the chains for all identifiable resources and record annotations at the journal level.
Bonus: Journal timeline visualisation
While digging around for some research on journal systems, I found these great visualisations on the beancount docs:
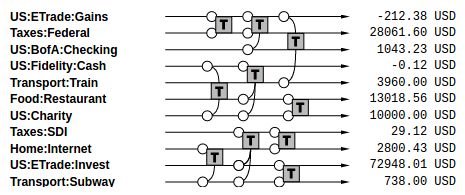
This graph displays transactions on a timeline where each transaction has arms reaching out to the accounts they impact. This could be a very useful as an appendix to various reports generated by accotron. I will look into how the SVGs are generated, but conceptually simple enough! Amending with hyperlinks to the underlying journals would be very useful too.
I am trying to design better visualisations for ledger and journal data in the end, and I love this graph for its ability to demonstrate (the complexity of) journal timelines in a digestible way.